watsonx.ai
With watsonx.ai modules in Make, you can infer the next tokens using a selected model and set of parameters in your watsonx.ai account.
To use the watsonx.ai modules, you must have an IBM watsonx.ai account. You can create an account at ibm.com/products/watsonx-ai.
Refer to the IBM watson.ai API documentation for a list of available endpoints.
Connect watsonx.ai to Make
To establish the connection, you must:
Obtain your API key in watsonx.ai
To obtain your API key from your watsonx.ai account:
Log in to your watsonx.ai account using cloud.ibm.com.
Click Manage > Access (IAM) > API keys.
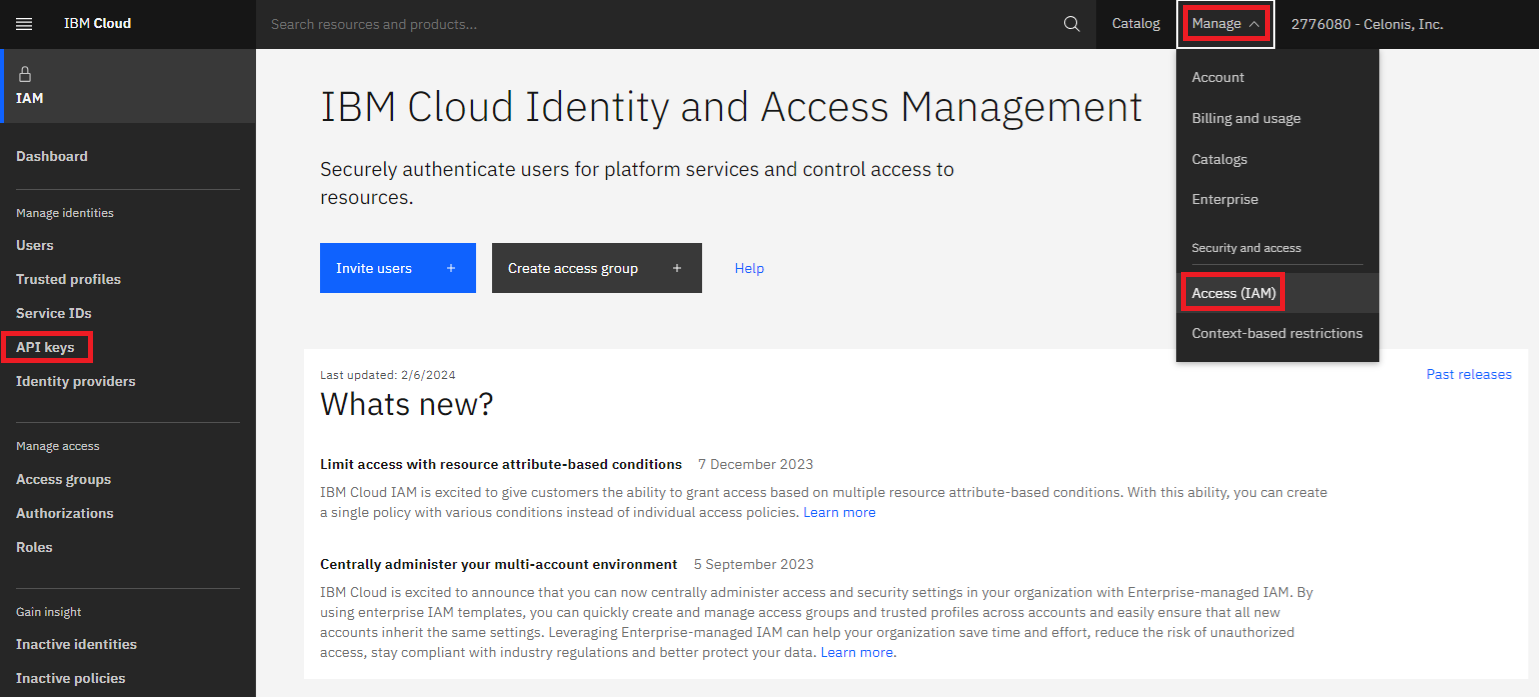
Enter a Name and Description for your API key and click Create.
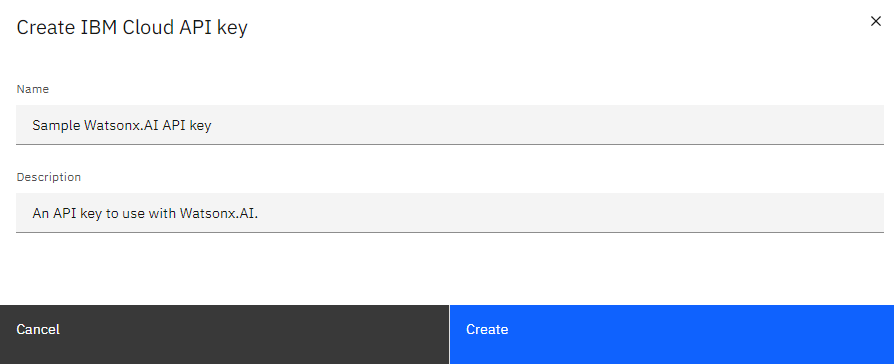
Copy the API key value shown and store it in a safe place.
You will use this value in the API Key field in Make.
Note
At the time of this publication, all steps for Obtain your API key in watsonx.ai were checked and verified to be accurate. However this may have changed, so please see the IBM watsonx.ai documentation for the most up-to-date directions.
Establish the connection with watsonx.ai in Make
To establish the connection in Make:
Log in to your Make account, add a watsonx.ai module to your scenario, and click Create a connection.
Optional: In the Connection name field, enter a name for the connection.
In the IBM Cloud Region field, select a region.
In the Connection Level field, select Space or Project.
If you selected Space for your Connection Level, enter your Space ID. If you selected Project for your Connection Level, enter your Project ID.
Your Project ID and Space ID can be found in your watsonx.ai account.
Project ID
Select the 4-bar menu in the upper-left corner, click Projects, and then click View all projects.
Select your project and click the Manage tab. Your Project ID is listed in your project details.
Space ID
The Space ID is shown in the model's URL in your browser’s address bar. Copy the part of the URL that follows
&space_id=.In the API Key field, enter the API key copied above.
Click Save.
If prompted, authenticate your account and confirm access.
You have successfully established the connection. You can now edit your scenario and add more modules. If your connection requires reauthorization at any point, follow the connection renewal steps here.
Build watsonx.ai Scenarios
After connecting the app, you can perform the following actions:
Text Generation
Infer the text with a selected model and a set of parameters.
Connection | Establish a connection to your watsonx.ai account. | ||||||||||||
Model ID | Select the model you want to use. | ||||||||||||
Input | Enter the prompt to generate completions. | ||||||||||||
Maximum New Tokens | Enter the maximum number of new tokens to be generated. The maximum supported value for this field depends on the model being used. How the token is defined depends on the tokenizer and vocabulary size, which in turn depends on the model. Often the tokens are a mix of full words and sub-words. To learn more about tokenization, see here. Depending on the users plan, and on the model being used, there may be an enforced maximum number of new tokens. | ||||||||||||
Minimum New Tokens | Enter the minimum number of new tokens to be generated. If stop sequences are given, they are ignored until minimum tokens are generated. | ||||||||||||
Temperature | Enter a a value lower than or equal to 2. This value is used to modify the next-token probabilities in sampling mode. Values less than 1.0 sharpen the probability distribution, resulting in less variability in output. Values greater than 1.0 flatten the probability distribution, resulting in greater variability in output. | ||||||||||||
Decoding Method | Select the decoding method you wish to use. Greedy decoding selects the token with the highest probability at each step of the decoding process. Sample decoding offers more variability in how tokens are selected. | ||||||||||||
Length Penalty | This setting can help to shorten the answers provided.
| ||||||||||||
Random Seed | Enter a value higher than or equal to 1. The random number generator seed is used in sampling mode for experimental repeatability. To produce repeatable results, set the same random seed value every time. | ||||||||||||
Time Limit | Enter the time limit in milliseconds. If not completed within this time, the generation will stop. Depending on your plan and on the model being used, there may be an enforced maximum time limit. | ||||||||||||
Top-K | Enter how many tokens to sample. Must be a number between 1 and 100. | ||||||||||||
Top-P | Enter a value lower than or equal to 1. The Top-P value specifies the cumulative probability score threshold the tokens must read. This is also known as nucleus sampling. | ||||||||||||
Repetition Penalty | Enter a value between 1 and 2. A higher value leads to more diverse and varied output. A lower value will increase the probability of repeated text. | ||||||||||||
Truncate Input Tokens | Enter a value to specify the maximum number of tokens accepted in the input. A value of 0 means the input will not be truncated. | ||||||||||||
Include Stop Sequence | Select Yes or No. Stop sequences are one or more strings which will cause the text generation to stop if/when they are produced as part of the output. Stop sequences encountered prior to the minimum number of tokens being generated will be ignored. | ||||||||||||
Return Options |
|
Other
Performs an arbitrary authorized API call.
Connection | Establish a connection to your watsonx.ai account. |
URL | Enter a path relative to |
Method | Select the method type.
|
Headers | Enter the desired request headers. |
Query String | Enter the request query string. |
Body | Enter the body content for your API call. |